Outline: robots are increasingly expected to operate in complex, real-world environments, but the machine learning methods that drive their decision-making, like reinforcement and imitation learning, often struggle with training stability and capturing the multimodal nature of behavior. This post introduces diffusion models as a powerful alternative for robotic decision making, explaining their core denoising mechanism and surveying their applications in several contexts. Full post
Outline: machine learning models, such as ChatGPT and those used in autonomous driving, are becoming essential tools in our daily lives. However, the existence of "adversarial examples" demonstrates that these systems are not free from vulnerabilities. The post, introduces the concept of adversarial examples and discusses Certifiable Robustness, a methodology designed to combat them. Full post
The Social Impact of AI Research: Lessons from the relAI…
Outline: explore the social impact of AI research through the lens of the relAI Ethics course. Valentine Idakwo, MD, MSc, discusses why AI models are "invisible blueprints" for society and how researchers can move from legal compliance to meaningful social justice. Full post
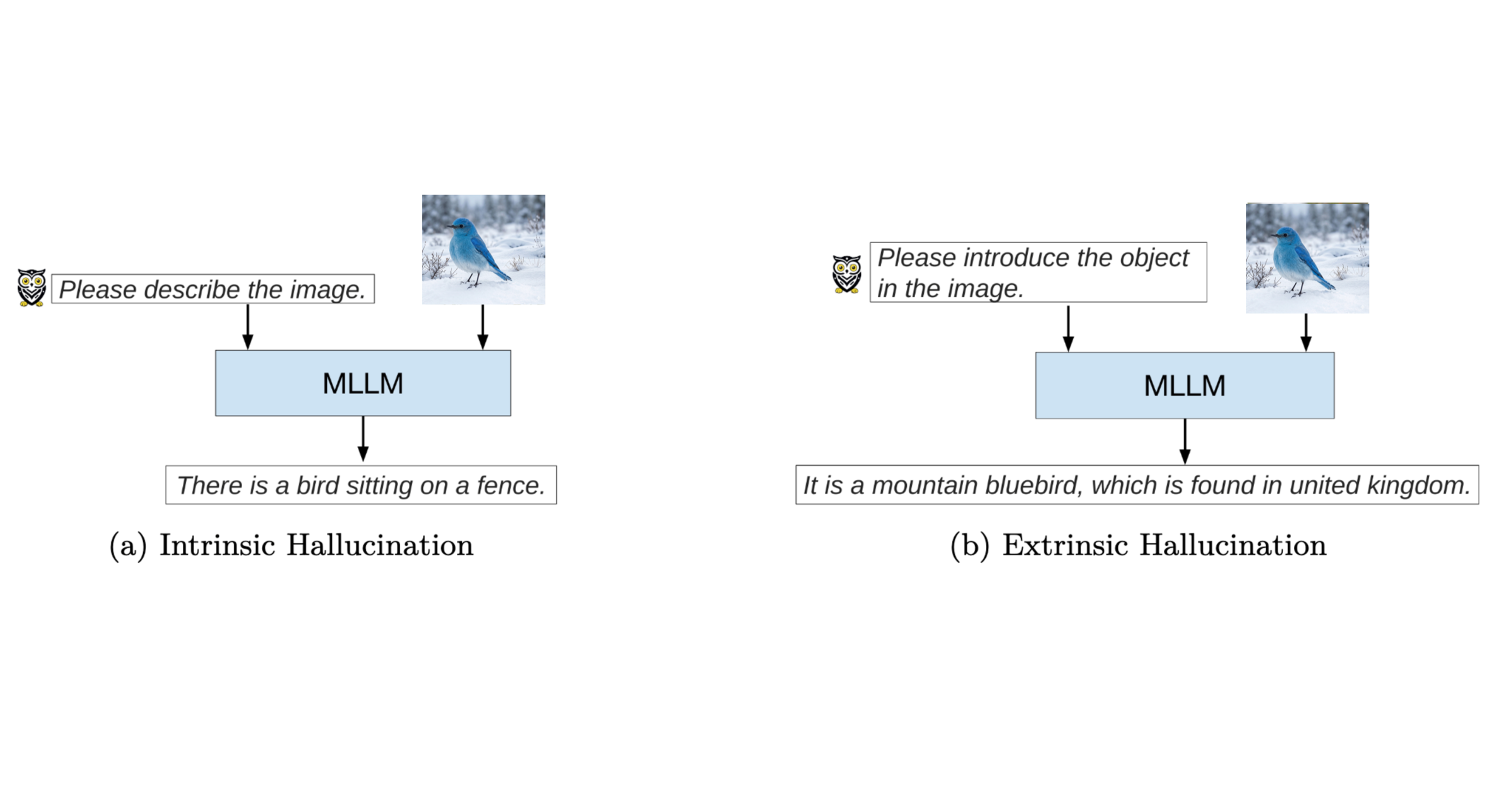
Outline: This post introduces hallucination in large language models—why fluent outputs can still be wrong, what distinguishes intrinsic from extrinsic errors, and how training data, model design, inference, and alignment contribute. It surveys detection and mitigation approaches and sets up later posts on toxicity, bias, and inclusivity in responsible textual generative AI. Full post
Random Convolutions: A Simple Way to Boost Generalization
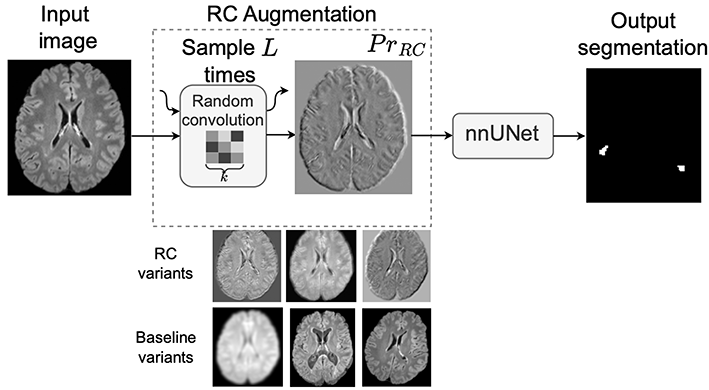
Outline: random Convolutions (RC) are a simple and effective data augmentation technique designed to improve the robustness of deep learning models, particularly in medical imaging. Instead of relying on fixed or learned filters, RC applies a small stack of randomly generated convolutional filters to input images during training. This introduces strong but controlled variations in image texture while preserving the underlying anatomical structure. By exposing models to a wide range of plausible appearance changes, Random Convolutions reduce overfitting to dataset-specific characteristics such as scanner type or acquisition protocol. In practice, RC acts as an implicit form of domain randomization, encouraging models to focus on stable, shape-based and contextual features rather than fragile texture cues. Despite its simplicity and low computational cost, RC has been shown to substantially improve generalization across institutions and imaging conditions in challenging tasks such as multiple sclerosis lesion segmentation. Full post
Neuromorphic Computing: A Brain-inspired Approach to Robot Intelligence
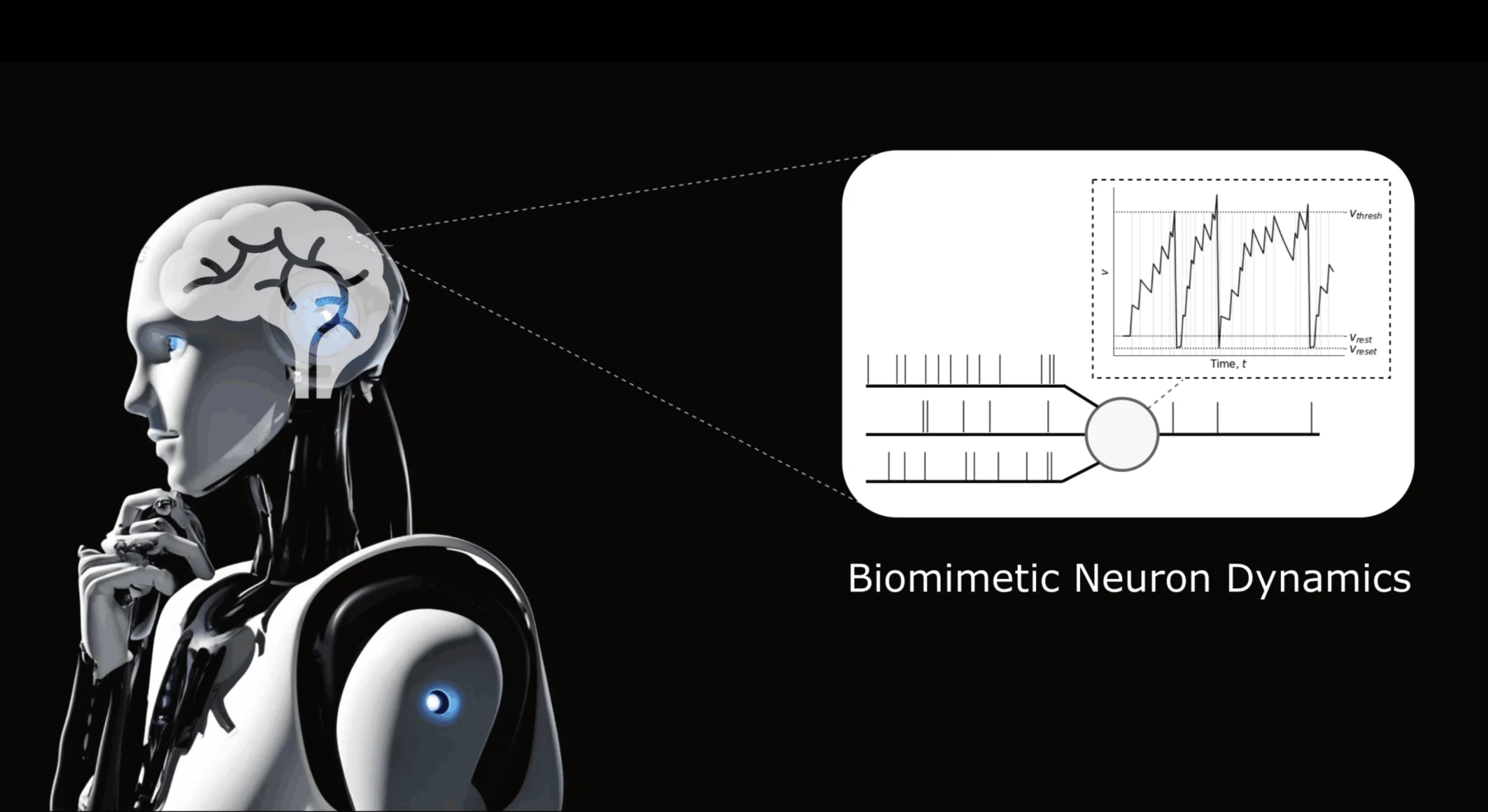
Outline: this post offers a high-level walkthrough of neuromorphic computing, why it matters for energy-efficient robot intelligence, and how SNNs, event cameras, and neuromorphic chips fit together Full post
Outline: this work explores how AI systems bridge the gap between understanding human instructions and performing real actions by learning through direct interaction with their environment. Full post
From Unlucky Strikers to Statistical Learning Theory
Outline: using the analogy of football striker, this post explains how statistical learning theory helps us understand when we can trust model predictions and empirical averages, highlighting the challenges of generalization in modern machine learning, especially with complex models like deep neural networks. Full post
Outline: machine learning systems are increasingly used to support decision-making processes. Yet, these systems do not merely reflect the world—they also reshape it. Once deployed, predictions can influence behaviors, alter policies, and redirect resources, creating feedback loops that change the very data-generating processes they aim to model. Full post
Outline: the post highlights the importance of moving beyond average treatment effects by quantifying the uncertainty of these estimates. It introduces a method using Makarov bounds and a Neyman-orthogonal AU-learner to provide reliable bounds on treatment effects, offering a clearer view of potential benefits and harms in high-stakes scenarios. Full post
What If Our Machine Learning Labels Aren’t What We Think…
Outline: this article discusses the issue of label uncertainty in supervised machine learning, highlighting limitations of majority voting. Next, it discusses the Bayesian mixture model to handle the uncertainty in labels. Full post
Outline: uncertainty quantification (UQ) is paramount in deploying machine learning models for safety-critical tasks. Among other shortcomings, many UQ methods rely on strict, hard-to-test, distributional assumptions. Conformal prediction provides a distribution-free alternative and has become a standard tool in the UQ shed. Full post
Causality Part I: Does eating chocolate make you smarter?
Outline: this article explains why correlation does not imply causation, using the example of chocolate consumption and intelligence. It further illustrates how confounding variables can lead to correlation and discusses statistical methods such as the instrumental variable approach to determine actual causal links. Full post
Using topological features to prevent topological errors
Outline: image segmentation is a prominent application of deep learning, but conventionally trained segmentation networks tend to make topological errors. Topological loss functions address this problem. But what does topological correctness mean? This post explains the basics of persistent homology, and how it can be used for machine learning. Full post
Outline: adapting a deep neural network to unseen data and tasks is imperative these days, however access to target data is often available. Common target adaptation techniques including domain adaptation and generalization train for meaningful representations during source training. Recent paradigms such as Test-time training/adaptation focus on optimizing the source model on unseen data. To do so, they finetune the model on the streaming unsupervised data which is useful for practical scenarios. Moreover, these techniques can be applied to variety of tasks such as regression, classification and segmentation. Full post
A gentle introduction to uncertainty quantification
Outline: uncertainty Quantification (UQ) is considered indispensable for predictive models in safety-critical applications. Modern models, though high-performing, struggle with providing meaningful uncertainty estimates due to a number of reasons. Full post
Outline: welcome to the relAI blog of the Konrad Zuse School of Excellence in Reliable AI (relAI). This blog will serve as a platform to share cutting-edge research and developments from our school, highlighting the significant strides we are making towards making AI systems safer, more trustworthy, and privacy-preserving. Full post