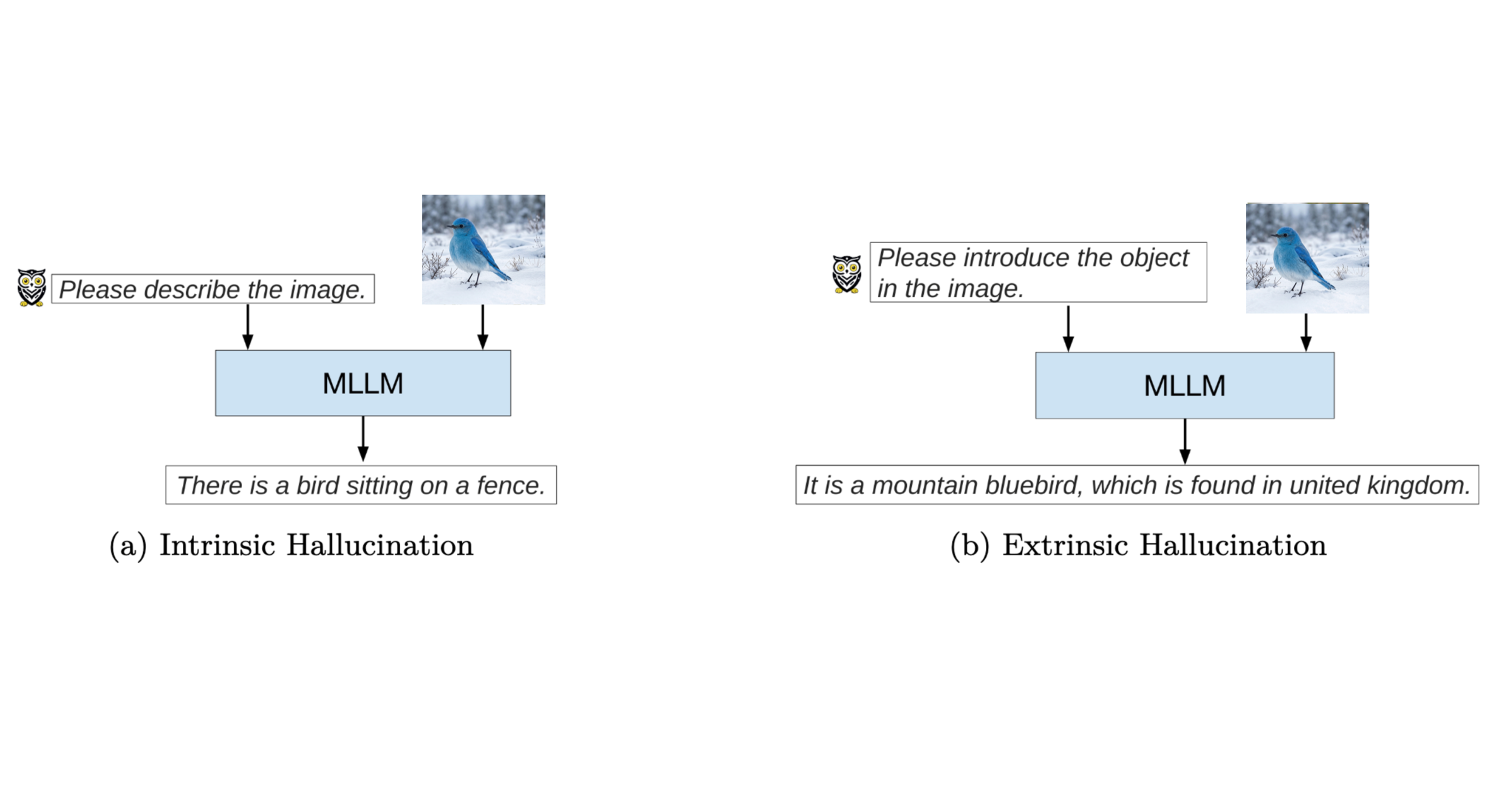
Figure 1: Multimodal illustration (MLLM). Subfigure (a): intrinsic hallucination—the output is inconsistent with the input (no fence appears in the image). Subfigure (b): extrinsic hallucination—the output adds a geographic claim that conflicts with a widely accepted fact (the species is associated with North America, not the United Kingdom). Source: Adapted from Ji et al. (2023). 2 The bird image is generated using a text-to-image model.
Welcome to the first post in my blog series on Responsible Textual Generative Models. In this series, I explore the core principles behind responsible AI development, focusing on how generative models can be designed and deployed in ways that are reliable, ethical, and socially beneficial. Topics will range from truthfulness and factual accuracy to toxicity mitigation and privacy protection.
In this post, I focus on one of the most fundamental responsibilities of generative models: producing truthful content. As AI systems increasingly shape how information is created and consumed, their ability to generate fluent text is no longer sufficient. Ensuring that generated content is reliable and grounded in reality has become a critical requirement for building trustworthy AI systems1.
Hallucination in AI: What’s the Problem?
Large pre-trained language models, such as GPT-family models, have transformed the landscape of content creation. With their ability to summarize lengthy documents, compose poetry, and answer complex questions, these systems have opened new possibilities for human–AI interaction. However, alongside these impressive capabilities lies a critical challenge: hallucination.
In the context of AI, hallucination refers to situations where a model generates content that is factually incorrect, unsupported by evidence, or entirely fabricated. These errors often appear fluent and confident, making them particularly difficult for users to detect.
The implications of hallucination can be severe across real-world domains. In healthcare, hallucinated outputs may recommend non-existent treatments, potentially endangering patients. In legal settings, fabricated precedents could mislead practitioners and influence judicial outcomes. Similarly, in journalism, factual errors in AI-generated articles risk misinforming the public and eroding trust in media institutions. These examples highlight why hallucination is not merely a technical flaw, but a serious societal concern.
As illustrated in Figure. 1, hallucinations can be broadly categorized into two types2:
- Intrinsic Hallucination from Figure 1(a): The generated content is inconsistent with the provided input. Here, the image shows a bird on a branch only; describing a fence is not supported by what is shown.
- Extrinsic Hallucination from Figure 1(b): The model introduces factual detail that goes beyond the image and, in this example, conflicts with common knowledge: the output places the species in the United Kingdom, whereas mountain bluebirds are associated with North America.
Why Does Hallucination Happen?
To effectively address hallucination, it is essential to understand why it occurs in the first place. The causes of hallucination are multifaceted, spanning training data, model design, inference strategies, and post-training alignment.
Bias in Training Data
Hallucination often originates from the data used to train large language models. These systems rely on massive, heterogeneous datasets, frequently collected from internet sources that may contain inaccuracies, biases, or outdated information. While such diversity improves linguistic coverage, it also increases the risk that models internalize flawed or incorrect knowledge3. As a result, errors present in the training data can be reproduced—or even amplified, during generation.
In short, imperfect data inevitably leads to imperfect factual knowledge.
Limitations of Language Models
Even when trained on high-quality data, the fundamental design of language models contributes to hallucination. These models generate text by predicting the most probable next token based on context, a process that optimizes fluency rather than factual correctness. Consequently, when faced with incomplete or ambiguous input, models may produce responses that sound plausible but lack grounding in reality4. This highlights a fundamental tension between linguistic coherence and factual accuracy.
Inference Strategies
Hallucination is also influenced by the strategies used during inference. Sampling techniques that introduce randomness are often employed to encourage diversity and creativity in generated outputs. While effective for open-ended tasks, these methods can increase the likelihood of factual deviations5. In the absence of clear constraints, models may invent information to maintain coherence, prioritizing engagement over correctness.
Post-Training Alignment
Efforts to align models with user preferences can also unintentionally exacerbate hallucination. Fine-tuning approaches that prioritize helpfulness or agreeableness may encourage models to generate confident answers even when uncertainty is warranted. This phenomenon, often referred to as sycophancy, can lead models to favor user satisfaction over factual integrity6. Balancing alignment with truthfulness remains a significant challenge.
Detecting and Measuring Hallucinations
Detecting hallucinations in AI-generated content is a challenging yet essential task. Over time, researchers have proposed a range of techniques that evaluate hallucination from different perspectives, each with its own strengths and limitations.
Overlap Metrics
One common approach to hallucination detection involves measuring the overlap between generated content and reference sources. Traditional N-gram-based metrics are computationally efficient but often fail to capture paraphrased or semantically equivalent content7. More advanced methods focus on entity consistency8, relational structure9, or contextual knowledge alignment10. While more accurate, these approaches typically require additional computational resources.
Fact-Checking Pipelines
Another effective strategy integrates external knowledge bases into the generation process. Fact-checking pipelines verify generated statements against trusted sources, improving factual reliability11. A prominent example is Retrieval-Augmented Generation (RAG), which combines generative models with real-time document retrieval to ground outputs in verifiable evidence12. This approach is particularly valuable in high-stakes domains such as healthcare and finance.
Uncertainty Modeling
When external knowledge sources are unavailable, uncertainty modeling provides a knowledge-independent alternative. By analyzing confidence signals in model outputs, low-certainty responses—often correlated with hallucination—can be identified3. However, this approach typically requires access to internal model states, limiting its applicability in black-box or API-based settings.
Automated Fact-Checking Systems
Recent advances enable models to evaluate their own outputs. Techniques such as multi-round self-evaluation allow models to identify internal inconsistencies across generations, flagging potentially hallucinated content14. These methods represent an important step toward self-correcting and more autonomous AI systems.
Strategies for Mitigating Hallucination
While detection focuses on identifying hallucinations after generation, mitigation strategies aim to prevent hallucinations from occurring in the first place.
Improving Data Quality
High-quality training data forms the foundation of reliable generative models. Reducing bias, misinformation, and ambiguity during data curation significantly lowers the likelihood of hallucination15. Careful dataset design ensures that models learn accurate and consistent representations of the world.
Innovating Model Architectures
Architectural innovations can further mitigate hallucination. Techniques such as incorporating truth-promoting objectives or external validation layers encourage models to prioritize factual correctness during training16. These approaches enhance robustness without sacrificing expressive capacity.
Post-Training Refinement
Fine-tuning models through techniques such as Reinforcement Learning with Human Feedback (RLHF) can be effective in aligning outputs with user expectations when the alignment objectives are carefully designed. As discussed earlier, naïve post-training alignment that prioritizes helpfulness or agreeableness may inadvertently exacerbate hallucination or sycophancy.
In contrast, RLHF frameworks that explicitly reward factual correctness, calibrated uncertainty, and evidence-based responses can improve reliability. When applied thoughtfully, such post-training refinements establish a feedback loop that balances user alignment with factual integrity, ultimately improving overall model performance.
Adjusting Inference Strategies
Inference-time interventions offer a flexible way to reduce hallucination without retraining models. Plug-in tools and external retrieval systems can be integrated during generation to provide factual grounding17. Additionally, recent work explores steering model activations toward truth-correlated latent directions, further improving factual alignment18.
Looking Ahead
Addressing hallucination is a cornerstone of responsible generative AI, as trust in AI systems fundamentally depends on their ability to produce truthful content. However, truthfulness alone is not sufficient. Responsible AI development must also consider issues such as toxicity, bias, and inclusivity.
In the next post in this series, I will examine the challenge of toxic content in generative models and explore strategies for producing outputs that are respectful, fair, and inclusive. Taken together with the posts that follow, these dimensions form the foundation of responsible textual generative AI.
References
1. Gu, J. (2024). Responsible generative AI: What to generate and what not. University of Oxford.
2. Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1–38. https://doi.org/10.1145/3571730
3. Huang, Y., et al. (2024). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems. https://doi.org/10.1145/3703155
4. Zhang, T., et al. (2023). How language model hallucinations can snowball. arXiv:2305.13534.
5. Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2020). The curious case of neural text degeneration. In International Conference on Learning Representations (ICLR).
6. Sharma, A., et al. (2024). Towards understanding sycophancy in language models. In International Conference on Learning Representations (ICLR 2024).
7. Maynez, J., Narayan, S., Bohnet, B., & McDonald, R. (2020). On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL).
8. Feng, X., et al. (2021). Entity-level factual consistency of abstractive text summarization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL-IJCNLP 2021).
9. Goodrich, B., et al. (2019). Assessing the factual accuracy of generated text. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
10. Shuster, K., et al. (2021). Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021.
11. Gou, Z., et al. (2024). CRITIC: Large language models can self-correct with tool-interactive critiquing. In International Conference on Learning Representations (ICLR 2024).
12. Chen, J., et al. (2023). Complex claim verification with evidence retrieved in the wild. arXiv:2305.11859.
13. Manakul, P., et al. (2023). SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. arXiv:2303.08896.
14. Wei, J., et al. (2023). Simple synthetic data reduces sycophancy in language models. arXiv:2308.03958.
15. Gu, J., et al. (2022). Controllable text generation via probability density estimation in the latent space. arXiv:2212.08307.
16. Yu, D., et al. (2023). Improving language models via plug-and-play retrieval feedback. arXiv:2305.14002.
17. Li, H., et al. (2023). Self-discovering interpretable diffusion latent directions. arXiv:2311.17216.