Deep neural networks often perform well on trained data. However, on unseen data they usually fail to generalize and accompany performance degradation (Vu et al., 2019). This degradation of performance affects systems deployed in real-world environments such as processing images for self-driving cars, processing street views, generating text, and examining cells and tissues through various scanners deployed.
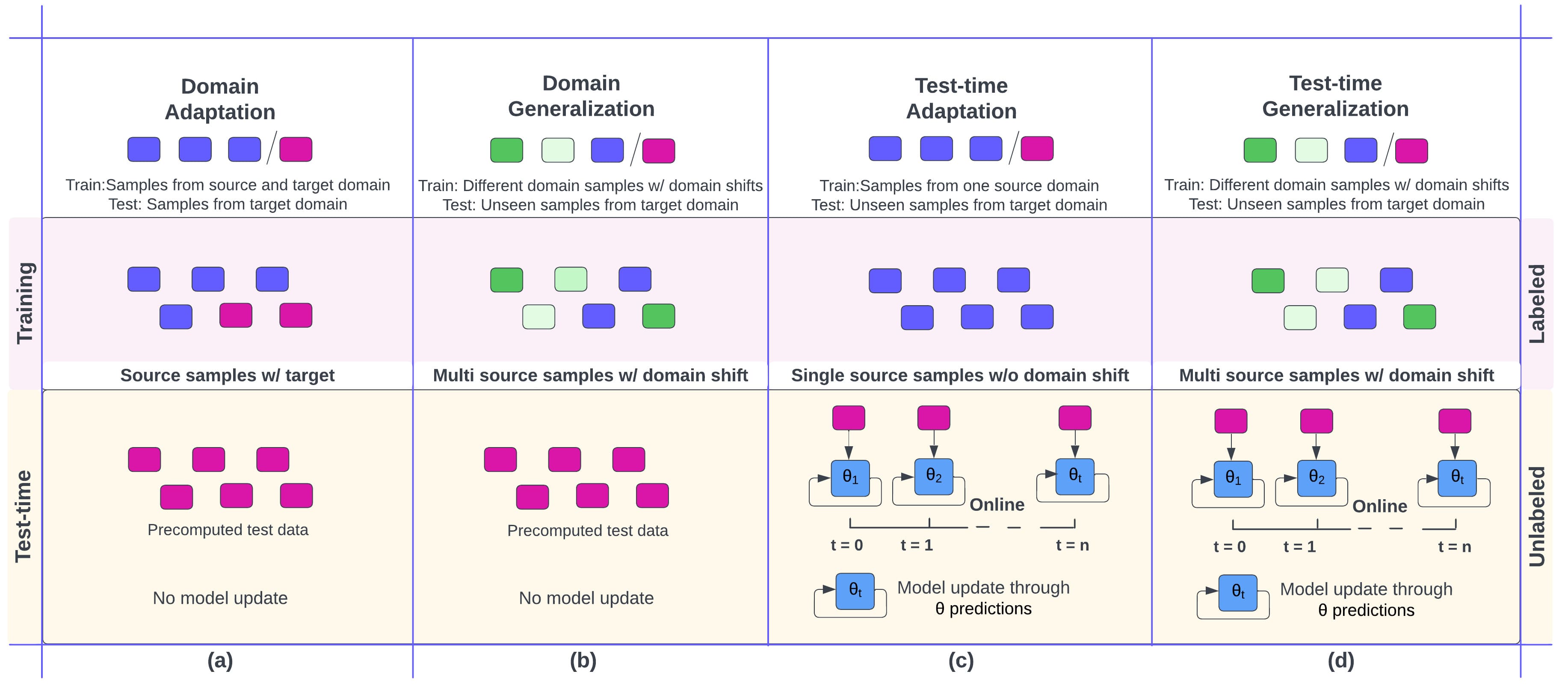
Figure 1: Illustration of domain adaptation and generalization mechanisms. Every color is indicative of sample with domain shift with pink consistently representing the test-data. Legends 'training' and test-time' provide an insight of the source training and target adaptation process.
To deal with such scenarios, domain adaptation (Figure 1a) and domain generalization emerged. Domain adaptation (Pandey et al., 2020) assumes access to target data and focuses on training a source model on the source domain, indicated with blue and pink samples in the training legend. At test time, it only focuses on evaluating the trained model on precomputed test data.
Common domain adaptation techniques focus on utilizing unlabeled target data. This assumption does not hold true in most of the cases since access to target data is only sometimes available. For instance, in scenarios such as self-driving cars (Vu et al., 2019), it is hard to collect all variations of road, weather, and scenes. Hence, domain generalization emerged to counter this.
Domain generalization (Muandet et al., 2013) (Figure 1b) assumes no access to target data while training a source model on multiple source domains indicated with different colors in the training legend. At test time, akin to domain adaptation, they evaluate precomputed test data. Existing methods focus on aligning the source distributions for invariant learning, training the model with meta-learning, augmenting domain data to resemble target or increase variations, and simulating the target data. However, since one cannot access target data or its distribution, these methods often come across overfitting and performance issues on the unseen target domain, known as the adaptivity gap.
To get closer to practical scenarios where access to target data is often not always precomputed, a recent paradigm Test-time adaptation (Wang et al., 2020) emerged (Figure 1c). In test-time adaptation, the source model is finetuned on target data as and when it arrives in small batches, as shown in the Test-time legend. For instance in scenarios this is the usual case in medical imaging applications where the imaging data from scanners is often available as and when the patient arrives. Moreover, the focus is to make the source model more target-specific by finetuning the model on target data. However, since access to such an unseen batch of samples is unlaballed, finetuning the model is challenging. Common methods utilize source model predictions and entropy on these batches to finetune the model.
Test-time generalization (Ambekar et al., 2023) (Figure 1d) focuses on training source models on multiple source domains during training while following the test-time adaptation setting at test-time. Recent methods such as (Ambekar et al., 2023; Xiao et al., 2022) focus on simulating domain shifts and test-domain and meta-learn the ability to generalize on unseen test data. Moreover, several methods also focus on addressing pseudo labeling, consistency, clustering, and self-supervision with auxiliary tasks.
Datasets and applications
Common tasks in deep learning include but not limited to Classification, speech recognition, medical imaging, computer vision, natural language processing. Moreover the common datasets utilized to evaluate method in classification and segmentation include DomainNet, Office-Home, Cifar corrupted, PACS, VLCS, Office-31, and NICO++.
Related topics
Transfer learning: One usually assumes access to labeled target data to evaluate and finetune the model. However, one doesn't assume access to labelled target data to fine-tune the model for all the paradigms above.
Zero-shot learning: This focuses on unseen label space changes between source and target, while the paradigms above focus primarily on generalizing the model to the unseen domain where new label space can seldom be a part of it.
Semi-supervised learning: Here, one assumes access to partial target set where the training and testing distributions come from the same distribution. However, the above paradigms do not focus on addressing the same distributions.
In summary, well-performing target models adapting to unseen target data is an omnipresent problem. Addressing these while being reminiscent of practical scenarios while being efficient remains an open problem.
References
Pandey, Prashant, Aayush Kumar Tyagi, Sameer Ambekar, and A. P. Prathosh. "Unsupervised domain adaptation for semantic segmentation of NIR images through generative latent search." In ECCV 2020
Bo Li, Yezhen Wang, Shanghang Zhang, Dongsheng Li, Kurt Keutzer, Trevor Darrell, and Han Zhao. Learning invariant representations and risks for semi-supervised domain adaptation. CVPR 2021.
Ambekar, Sameer, Zehao Xiao, Jiayi Shen, Xiantong Zhen, and Cees GM Snoek. "Learning Variational Neighbor Labels for Test-Time Domain Generalization.", CoLLAs 2024
Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. CVPR 2019.
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. ICLR 2021
Abhimanyu Dubey, Vignesh Ramanathan, Alex Pentland, and Dhruv Mahajan. Adaptive methods for real-world domain generalization. CVPR 2021
Muandet, Krikamol, David Balduzzi, and Bernhard Schölkopf. "Domain generalization via invariant feature representation." ICML 2013.
Xiao, Zehao, Xiantong Zhen, Ling Shao, and Cees GM Snoek. "Learning to generalize across domains on single test samples." ICLR 2022.