Machine learning (ML) technologies are set to revolutionize various fields and sectors. ML models can learn from text, image and various other forms of data by automatically detecting patterns. Their successful application, however, relies heavily on access to extremely large datasets (some state-of-the-art language models are trained on the whole internet). For many interesting applications, such datasets contain sensitive information (e.g. medicine and patient data), thus precluding the application of ML. This is because ML models store some of their training data nearly verbatim and have been shown to be susceptible to a wide range of attacks [1, 2, 3], which can reveal sensitive aspects of the training data.
In this blog post, we will provide a short and simple explanation of differential privacy (DP), a technical solution that preserves privacy while allowing us to still train accurate ML models on datasets containing sensitive information. DP provides provable and quantifiable privacy protection to individuals sharing their data for model training or, in fact, any other form of data processing.
A non-technical primer on DP
In essence, DP states that the result of any data processing is "roughly" the same, no matter which individual's data is removed from (or added to) a dataset. Conversely, this means that a differentially private computation cannot depend very much on any single individual's data in a dataset. As a result, DP prevents potential adversaries from learning specific details about any individual in a dataset while still allowing anyone to study trends and population characteristics of the data. Putting this into context: DP applied to a pancreatic cancer dataset prevents anyone from inferring if a given patient was a member of this dataset (and thus if they have cancer), while still allowing researchers to study the properties of pancreatic cancer and its causes.
DP is inherently tied to the concept of public release of summary statistics, where "summary statistics" can also be a machine learning model (or e.g. the average height ). In fact, the output of any computation that involves private information in some form is considered sensitive and is thus releasable under DP. The terminology used to describe DP often revolves around "queries on databases/datasets" because this phrasing captures the essence of a wide array of operations, from statistical analysis to machine learning, maintaining generality across applications. Finally, achieving DP involves the strategic insertion of randomness somewhere into a computation, which serves to obscure the contributions of individual data points.
Towards a slightly more technical definition
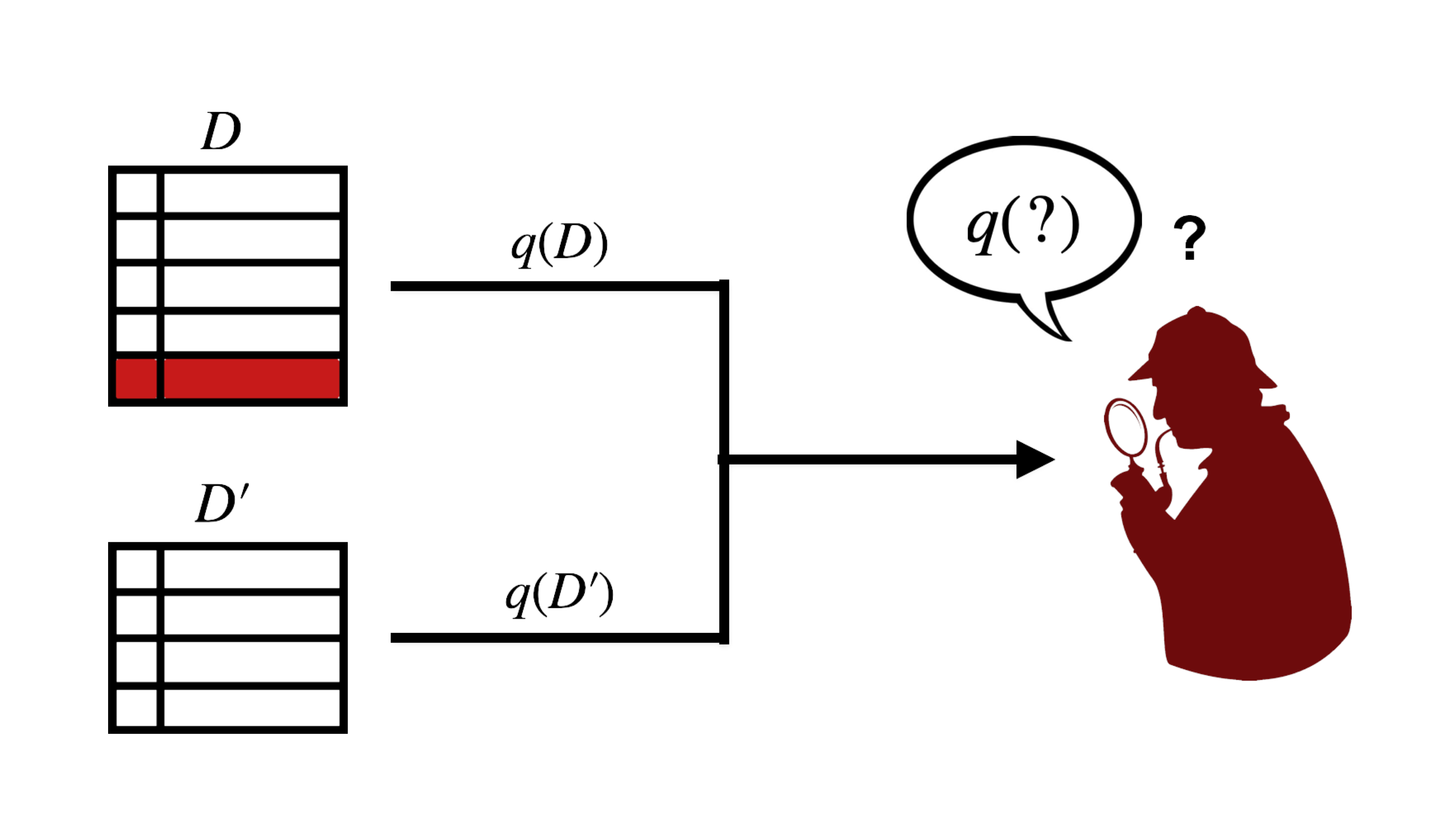
DP relies heavily on the concept of dataset adjacency, which might sound complicated at first but really isn't. Two datasets  and
and  are called adjacent (denoted by
are called adjacent (denoted by  ) if they differ by one individual's data (typically one row in a dataset; shown below in red):
) if they differ by one individual's data (typically one row in a dataset; shown below in red):

Being able to establish this adjacency relationship is essential for satisfying DP. DP is so powerful because it protects against worst-case privacy leakage, no matter how much an individual's data stands out from the rest of the dataset. This means that and are picked such that the difference between the output of the query  (which we wish to privatise) under and is maximised (i.e.
(which we wish to privatise) under and is maximised (i.e.  ). This quantity is called the query sensitivity. Note that, here, we do not consider the actual values in or but are concerned with the maximum possible change in
). This quantity is called the query sensitivity. Note that, here, we do not consider the actual values in or but are concerned with the maximum possible change in  caused by the removal of one single individual's data. For example, if is a function that returns the number of persons that are HIV positive in a dataset, then the query sensitivity is 1. This is because the result of a counting operation can only change by a maximum value of +1 or -1 when any datapoint is removed.
caused by the removal of one single individual's data. For example, if is a function that returns the number of persons that are HIV positive in a dataset, then the query sensitivity is 1. This is because the result of a counting operation can only change by a maximum value of +1 or -1 when any datapoint is removed.
Constructing a query function that satisfies DP then simply means that any output of is similarly likely to have been produced by or . A popular definition,  -DP, requires any output of to have multiplicatively similar probability under and :
-DP, requires any output of to have multiplicatively similar probability under and :
![\[p\left(q(D)\right) \leq \varepsilon \; p\left(q(D')\right)\]](https://zuseschoolrelai.de/wp-content/ql-cache/quicklatex.com-740a3fe2ae0241a1456cb912a5f0b2e7_l3.png "Rendered by QuickLaTeX.com")
If by itself does not achieve the above condition (this is often the case), we can add statistical noise to achieve the above condition (simple Gaussian or Laplacian noise suffices if scaled appropriately). Conversely, the above equation means that it is impossible (or very hard, depending on the choice of ) for an adversary, attempting to break privacy, to confidently distinguish between the outputs of  and
and  . This is crucial, as not being able to distinguish between and implies a direct upper bound on how well any adversary can reconstruct any datapoint [4].
. This is crucial, as not being able to distinguish between and implies a direct upper bound on how well any adversary can reconstruct any datapoint [4].

For many applications achieving a small (sometimes called a privacy budget), that is making and basically impossible to distinguish, is difficult and usually leads to very noisy, low-quality results. Improving this, so-called, privacy-utility tradeoff is a central research focus in the DP community. ML practitioners are in luck: it was recently shown that it's possible to train highly accurate models with small privacy budgets using a few simple tricks [5].
The essence
DP provably protects privacy by preventing a query's output from changing significantly due to the removal of any individual's data in a dataset. This implies that it is impossible for anyone to learn specifics about any individual's data in dataset while still allowing legitimate users to learn trends in the dataset.
Real-world use cases
Differential privacy is in the process of becoming a mature technology and is already being deployed in a number of real-world applications involving sensitive data. Some of these are listed below:
- Apple (typing suggestions, emoji suggestions, lookup hints)
- Google (typing suggestions, mobility data)
- LinkedIn (user engagement data)
- US Census (demographic data of US citizens)
To conclude, balancing the requirements of DP and accuracy in such large-scale applications will remain a hot topic for future research.