
Figure: Conceptual image depicting uncertainty in machine learning labels and annotator disagreement, featuring diverse annotators making varied assessments. Image generated by an AI model.
Supervised Machine learning (ML) has become a powerful tool for solving complex problems across industries. From diagnosing diseases to automating hiring processes, its potential is undeniable. However, the reliability of machine learning models depends heavily on the quality of the labels used during training. But what happens when those labels aren't as accurate or consistent as we assume? This question is critical, especially in sensitive domains where errors can have significant consequences.
In this article, we explore the challenge of label uncertainty in supervised learning, discuss why traditional strategies like majority voting may not always be appropriate, and introduce a statistical approach to better handle ambiguous or conflicting labels. Our analysis focuses on natural language inference (NLI), a task particularly prone to disagreement among annotators, and builds on the findings from our recent paper More Labels or Cases? Assessing Label Variation in Natural Language Inference 1
What Is Natural Language Inference?
Natural language inference (NLI) is a key task in natural language processing (NLP) where the goal is to determine the relationship between two sentences—a premise and a hypothesis. The relationship can be classified into one of three categories:
- Entailment: The hypothesis logically follows from the premise.
- Contradiction: The hypothesis directly contradicts the premise.
- Neutral: The relationship between the premise and hypothesis is unclear or unrelated.
For example:
- Premise: A boy in an orange shirt sells fruit from a street cart.
- Hypothesis: A boy is a street vendor.
The relationship is classified as entailment because the hypothesis is true based on the premise.
NLI is challenging because language is inherently ambiguous. Annotators may interpret sentences differently depending on context, personal background, or cultural influences. This makes NLI an excellent case study for examining label uncertainty. For this, labels from multiple annotators are collected to examine their (dis-)agreement.
In the following example, out of 100 annotators, 53 annotators vote for "neutral", 46 for "contradiction" and 1 annotator for "entailment":
- Premise: A woman holding a child in a purple shirt.
- Hypothesis: The woman is asleep at home.
Sources of Label Uncertainty
Label uncertainty in machine learning may arise from multiple factors, sometimes even simultaneously. Understanding these sources is key to improving model reliability and making better use of uncertain annotations. Such uncertainty arises in several ways:
Annotation Errors: Simple mistakes, such as misclicks in annotation tools, can lead to incorrect labels.
Disagreement Among Annotators: In subjective tasks like NLI or medical diagnosis, different annotators may provide different labels for the same data point. For instance, one annotator might interpret a pair of sentences as neutral, while another sees them as contradictory.
Ambiguity in the Task: Certain tasks are inherently ambiguous. In NLI, linguistic context and individual interpretation often result in varying labels. For example, a sentence pair might have elements of both entailment and neutrality, making it difficult to choose a single label.
Such variations are not just noise—they reflect the complexity of the problem and provide valuable information that simple majority voting may discard.
Moving Beyond Majority Voting
A common approach to handle label uncertainty is to collect multiple labels for each data point and use the most frequent label (majority vote) for training the ML model. While this works for simple cases where errors are rare, it overlooks nuanced scenarios:
Ambiguity: In ambiguous cases, the distribution of labels provides insights into uncertainty that majority voting ignores. For instance, a 51-49 split in votes for two classes tells a very different story than a 95-5 split.
Imbalanced Importance of Labels: Majority voting treats all classes equally, which can lead to poor decisions when one class carries more significance than others. For example, in medical diagnosis, suppose a model is trained to classify chest X-ray images into three categories: "Healthy", "Unsure", and "Disease Present". If 55% of annotators vote for "Unsure," 40% for "Disease Present," and only 5% for "Healthy," a majority voting approach would label the image as "Unsure." However, ignoring the 40% of annotators who flagged the disease could be a dangerous oversight.
A Bayesian Approach to Discover Latent Truths
To better address label uncertainty, we used a Bayesian mixture model. This statistical method assumes that each instance has a latent “true” label, and the observed votes are a reflection of annotators' interpretations of that label.
Key Components of the Model
Prior: Assume a latent ground truth label for each instance. This reflects our belief that one true label exists for the data point, even if it's not directly observed.
Likelihood: Model the relationship between the latent true label and the observed labels. For example, if the true label is "entailment," the likelihood quantifies how likely annotators are to vote for "entailment" versus "neutral" or "contradiction."
Posterior: Using Bayes' theorem, calculate the probability of the latent true label given the observed votes. This posterior distribution represents the refined estimate of the true label, incorporating both the data and prior assumptions.
An interested reader can check chapter 4 in Gruber et al. (2024)1 for details on the math and estimation procedure.
Insights from the ChaosSNLI Dataset
To better understand label uncertainty in NLI, we analyzed the ChaosSNLI dataset. This dataset is unique because each instance is annotated by 100 different annotators, providing a detailed view of label variation. The high number of annotations allows us to investigate human disagreement and the inherent uncertainty in labeling.
Visualizing Label Uncertainty
We developed a novel visualization tool to examine the distribution of votes for each instance in ChaosSNLI. Below is a figure, which illustrates the relationship between annotator votes and the estimated latent classes using our Bayesian model:
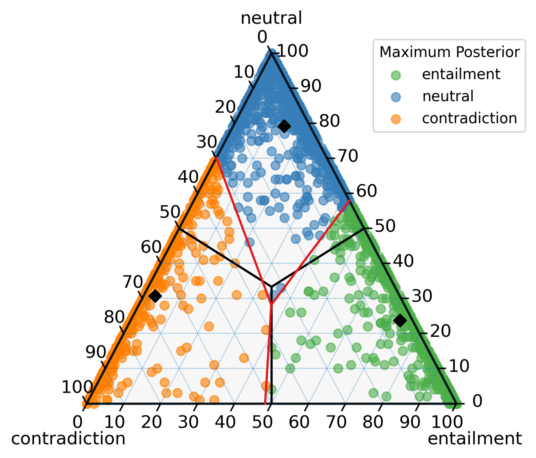
Figure: A scatter plot1 of the ChaosSNLI vote distribution. Each point represents one instance, positioned based on the proportion of votes for entailment, neutral, and contradiction.
What can we see?
- Each point in the scatter plot represents an instance, with its location determined by the proportion of votes for the three classes: entailment, neutral, and contradiction.
- Corner points represent instances where all votes belong to a single class (e.g., 100% entailment). Points closer to the center indicate higher uncertainty, with votes spread across multiple classes.
- The black lines show the borders of class membership based on majority voting, while the red lines show the boundaries of the latent classes estimated by our model.
- The black diamonds represent the center points of the latent classes, i.e., the most likely vote distribution for the respective classes.
What do the results tell us?
Our Bayesian model refines the classification of ambiguous instances. For example, many instances classified as "neutral" by majority voting are reassigned to "entailment" or "contradiction" based on the latent class distribution. This refinement reveals that "neutral" is often used as a fallback category when annotators are uncertain, leading to a loss of valuable information in traditional approaches. Analyzing the latent labels thus provides insights into the task itself, and additionally the labels can be used in downstream tasks, like training a ML model.
Practical Insights from Our Research
Our analysis of the ChaosSNLI dataset highlights the following insights:
- More Labels, Fewer Cases: The stability of our Bayesian model improves with an increased number of labels per instance, even if fewer instances are labeled overall. This suggests focusing annotation efforts on fewer but more thoroughly labeled cases, if annotation budget is limited.
- Refinement of Ambiguous Labels: By considering the full distribution of votes, our model can refine ambiguous categories like "neutral" and provide a more nuanced representation of uncertainty.
- Visualization as a Tool: Visual tools like ternary plots help us understand how annotators disagree and where the model diverges from majority voting.
Limitations and Future Directions
While our Bayesian approach is robust, it has limitations:
- Annotation Requirements: Multiple annotations per instance are needed, which may not always be feasible.
- Scalability: Extending this approach to visualize tasks with more than three classes or continuous labels requires further development.
- Integration into ML Pipelines: Incorporating these refined labels into predictive models is a promising area for future research.
Despite these challenges, our approach provides a strong foundation for addressing label uncertainty in machine learning.
Conclusion
Label uncertainty is an inherent part of supervised learning, especially in subjective or ambiguous tasks like natural language inference. By moving beyond majority voting and embracing statistical models like Bayesian mixture models, we can better understand and address this uncertainty. This leads not only to more reliable ML models but also to a deeper appreciation of the complexity of human annotations.
In our study, we showed that "multiple labels are a crucial building block for properly analyzing label uncertainty." As machine learning continues to evolve, methods like ours will play a critical role in ensuring its trustworthiness and reliability.
References
1. Gruber, Cornelia, et al. "More labels or cases? assessing label variation in natural language inference." Proceedings of the Third Workshop on Understanding Implicit and Underspecified Language. 2024



